排序算法
今天来说点简单的东西,排序算法。
排序问题应该是目前业务场景中出现的比较多的问题,程序员们学习编程算法所接触到第一个比较复杂也比较有用的算法应该就是冒泡排序算法了,所以说排序算法对于程序员们来说是既陌生又熟悉的存在。
很多编程教程中或者算法书中都对排序算法进行过一番介绍,而且对这些算法的性能作出比较,然后使用时间复杂度或者空间复杂度来描述他们的优劣,但是恐怕很多人都没有一个直观感受,但是只通过时间复杂度函数判断这些算法孰优孰劣的,这种做法有时候对一些算法是很不公平的。
这里,我主要通过我写的这些小程序,对现在流行的几大算法进行介绍并对他们的速度进行一下比较,有需要的话欢迎联系我~
同样是O(n*log(n))的算法表现上的差异说不定会让你大吃一惊。
介绍算法过程中后面的结果由于受到绘图函数的限制,不代表最终算法的表现,所以无参考价值。
在最后文末会有这些算法公平竞争比赛,如果有需要可以直接拉至文末查看~
为了方便起见,这里算法全部都为递增排序。
选择排序
这应该是最简单的算法了,算法就是遍历所有元素找到最小的一个放入第一个位置,然后在剩下的单位中重复刚刚的过程,直到剩余一个元素。
这个没啥好说的,我们来看一下这种算法的实际展示和表现:

最终数据访问和耗时结果为:

插入排序
这个排序跟选择差不多,其实大家在整理扑克的时候用的差不多就是这种方法:从第一张向后遍历,与前面已经形成有序队列的元素进行比较,找到前面一个比自己小后面一个比自己大的位置把自己插入到这个位置,直到最后一个元素。
这个算法在没有优化的时候是很慢的,下面是它的展示(时间关系,只能选择小数据量):

最终数据访问和耗时结果为:

希尔排序
这个简单一句话概括就是优化后的插入排序,插入的性能瓶颈主要就是交换次数过多,往往每插入一个数据都要交换好多次,希尔主要解决了交换次数过多的问题,先以大步长把数据进行插入排序,然后逐步缩小步长,直到步长变为1。这样做可以先以较少的代价把数据进行整理,将较大数据向后移以有效降低后面可能发生的交换次数,最后再以最基本的插入排序排列数据,此时数据已经接近有序也就几乎不会发生几次交换。
希尔排序的关键是步长变化的选择,不同的步长变化时间复杂度会有很大区别。希尔第一次提出它的时候建议初始步长为数据的一半,然后每次再取一半,直到变成1,但是这个步长其实效率并不高,Wiki上面有多个希尔排序的步长可供选择,这里我选择了一个速度较快的5/11。
算法演示:

最终数据访问和耗时结果为:

冒泡排序
这个估计大家都不陌生,算法也不复杂,就跟水中气泡,大的肯定先到顶,小的后到顶道理是一样的,算法就是先从头到最后,发现后面元素比前面元素小就交换二者位置,这样最大的就到最后了,然后从头到倒数第一个重复刚刚的过程,以此类推直到头部。
这个算法确实很美妙,而且有一定的实现复杂度www,所以被很多教材拿出来当入门教程,但是说实话,这个算法并不实用,因为电脑毕竟无法模拟出水泡那样的并行速度,所以他可以说是最慢的算法,没有之一。
算法演示:

最终数据访问和耗时结果为:

鸡尾酒排序
听名字你可能不知道它是啥,其实简单点描述就是双向冒泡排序,同时筛选出最大和最小的元素然后向中间靠拢。
但是跟冒泡排序一样,理想很美满,现实很骨感233。
算法演示:

最终数据访问和耗时结果为:

归并排序
归并也是比较常见的排序之一,归并有两种实现方式,一种是保持原数列归并,一种是另起一个数列归并,这里我实现的是后者。
归并的思想也很简单,就是把两个有序队列合并成一个更大的队列,但是队列刚开始是无序的,所以最初是以一个到两个元素为开始,逐步合并,直到合并范围达到整个数组。
归并往往以递归的方式进行实现,算法也比较简洁。
算法演示:

最终数据访问和耗时结果为:

快速排序
明星排序之一(这货确实是明星!)。
快速排序算法简单描述就是从队列中选择一个元素为基准,然后把小于它的放到它左边,大于它的放到它右边,这时候队列被一分为二,然后左边的和右边的队列重复这个过程,直到最终需要排序的元素剩余一个。
这个算法真的很厉害!这个算法真的很厉害!这个算法真的很厉害!重要的事情要说三遍。
算法演示:

最终数据访问和耗时结果为:

堆排序
依旧是明星排序,这个排序应该是最漂亮的排序(个人观点)。
这个排序大家应该都不陌生,由于队列和堆可以完美转换,所以就诞生了这么个排序算法(队列转换成堆请参阅完全二叉树的存储形式)。
这个算法就是先建立大顶堆,然后把头元素与最后的元素交换并将其移除队列,然后重新调整堆为大顶堆,重复这个过程。
堆排序主要是要实现建堆和调整堆的过程。
算法演示:

最终数据访问和耗时结果为:

插旗排序
嗯……就跟他名字一样,这个排序就是往一堆格子里面插旗,很形象。
算法简单描述:根据最小和最大的值,建立从最小到最大值的一系列格子,然后遍历队列,在访问到数据数值的位置上对数据进行进行计数(如数据为3就在格子3位置记录一次),最后读取所有格子,格子上对应的数字就是数据出现的次数,输出相应个数的数据即可。
这个算法确实很快,但是缺点也很明显:首先要知道数据极值,其次很耗费空间。当你的数据差很大的时候,这个算法很可能吃光你的内存资源。
算法最大的特点:数据无需进行相互比较。
算法演示:

最终数据访问和耗时结果为:

基数排序
其实我感觉这个有点像优化过的插旗排序。
基数排序有两种实现方式,一种是MSD,一种是LSD。
LSD中,数据从地位开始,先以最低位hash值将数据分类(一般就是这位上的数值),然后按照顺序取出,然后升高一位重复刚刚的过程,直到最高位,这时候数据就变成有序的了。
MSD则是从数据最高位开始,先以最高位hash值将数据分为若干块,然后降低一位,对每一块分别进行刚刚的过程,直到到最低位,最后取出数据即为有序的数据。
他们的优缺点与插旗排序一样,不过只需要知道数据最大值,耗费空间上比插旗好一点。
同样的,这个算法中数据无需进行相互比较。
算法演示:
LSD:

MSD:

最终数据访问和耗时结果为:
LSD:

MSD:

双调排序
这个排序在最近通用计算火热之后得到了很多人关注,因为这个算法很容易实现并行的通用计算。
算法核心是双调归并。什么是双调呢?简单来说,一个队列中,如果先递减后递增或者先递增后递减,那么他就是一个双调队列。归并双调的过程也很简单,从递减序列和递增序列的第一个元素开始比较,将较小的放到前面较大的放到后面,直到递减/递增序列的最后一个,然后把数据从中间拆成前后两个队列重复这个过程,直到最后剩余两个数据比较,这时候序列就变得有序。
双调的实现比较苛刻,数据量必须以二的幂为基准,否则无法构成双调序列,所以这种方法的缺点就是使用条件苛刻,虽然可以通过补全来应用到所有情况,但是补全的过程还会占用一定资源。
实现方式一般还是采用递归实现,跟归并类似,不过目标不是两边有序而是左右构成双调,然后对双调进行合并。
PS:双调排序并没有要求先减后增或者先增后减,两种形式都可以实现,你甚至可以把他们穿插到一起。
算法演示:

最终数据访问和耗时结果为:

对比
这么多算法,肯定你也听说过他们的时间复杂度,比如堆排序是O(n*log(n)),归并排序也是O(n*log(n)),但是这一简单的量级描述真的就说明他俩速度相当?
所以下面我们就来看看这些算法的速度对比吧,结果或许会令你感到意外。
这里所有的算法都以线程为单位同时开始,阈值为20s,超过者淘汰出去然后增大数据量继续比较。
首先我们先来个少一点的数据:
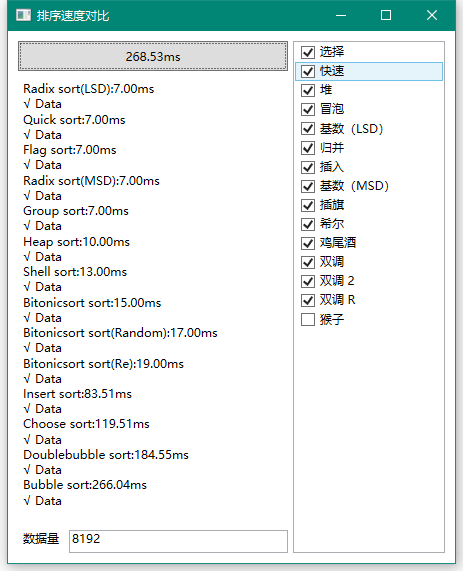
emmmmm……看来不够大家塞牙缝的,那好我们就来个大一点的:
在数据量没上10w的时候,冒泡和鸡尾酒已经基本撑不住了,紧随其后的是选择排序和插入排序。
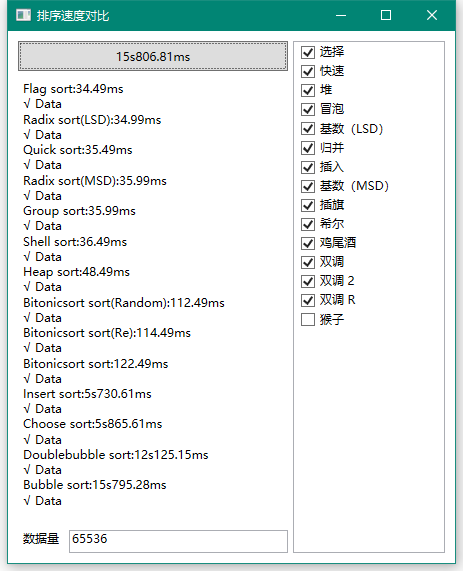
那么我们进一步扩大数据:
两个花瓶算法:冒泡和鸡尾酒已经很拖大家后腿了,其他人早早完成了任务然后在这里等了他们俩半天,然而还有两个目前也已经被淘汰,那就是在上一轮紧随其后的插入和选择。剩下的算法依然难分伯仲。
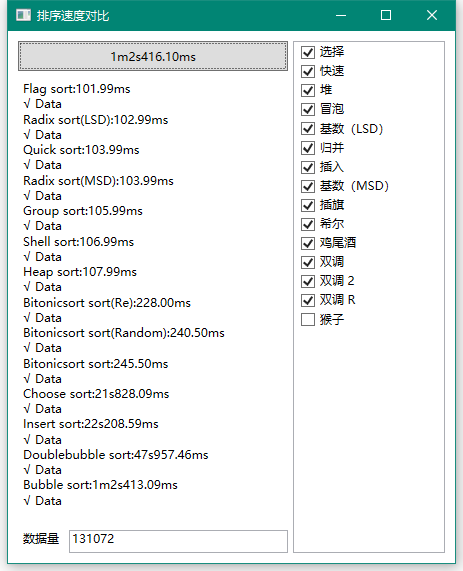
下面我就直接上他们差距最大的数据量了:
堆排和双调同时出局,但是同样是O(n*log(n))的归并却依然坚挺,是不是有点意外?估计令你更意外的是遥遥领先的快速排序,真的神奇。而且本次结果也可以看出希尔已经力不从心了,它能坚持过下一轮吗?
继续拉大数据量:
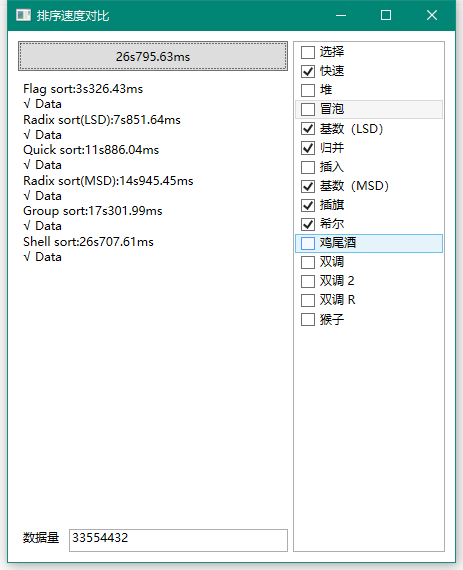
果然希尔被淘汰了,注意这里的希尔使用的是5/11步长变化,不一定是最优步长但是时间复杂度已经很低,也可能有其他表现不错的希尔步长,这里不再一一对比。
剩下的排序算法们还能坚持多久呢?
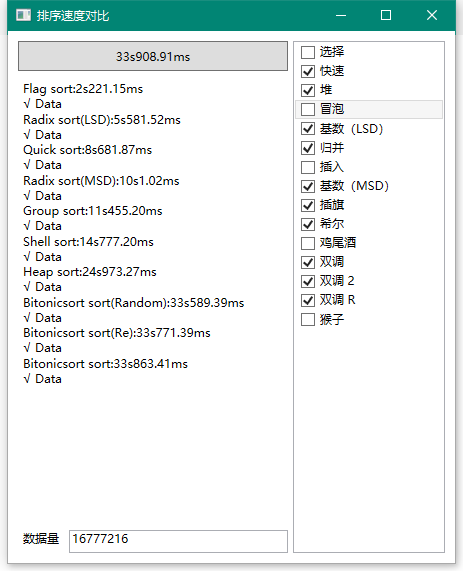
继续:
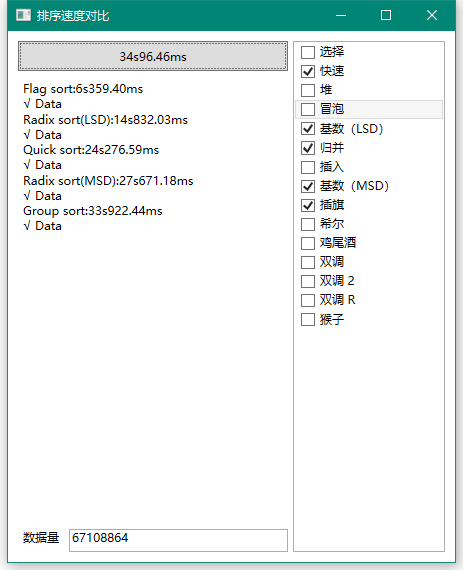
快排、基数(MSD)和归并出局,你是不是有点意外,快拍竟然在最终淘汰时表现都要好过基数的MSD形式,真的无敌……
剩下的这俩估计也不需要比较了,胜负已分,插旗无疑是最快的。
总结
这样的对比或许你会对这些排序算法有了新的认识,并不是说所有O(n*log(n))性能就差不多,他们的差别其实很大,要根据使用场景合理选择这些排序算法。
另外,快速排序并没有耗费很多空间,但是在排序速度上面竟然表现不俗(归并,你看看人家),这真的是很令人意外的,但是快排并不是无敌的,需要处理数据已经有序的特殊情况,可能会造成递归调用过深而溢出,同时也使得速度降为O(n^2)。
希望本文对你有帮助,多谢阅读~
花絮
猴子排序?人家也不是不能用哦!
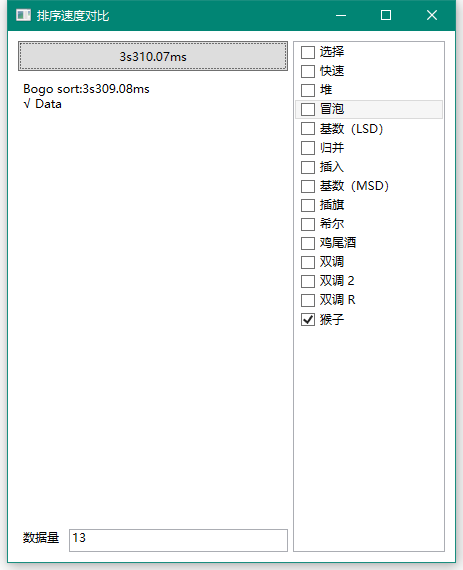
然而你排13个数据就用了3s,当你要排14个数据时……
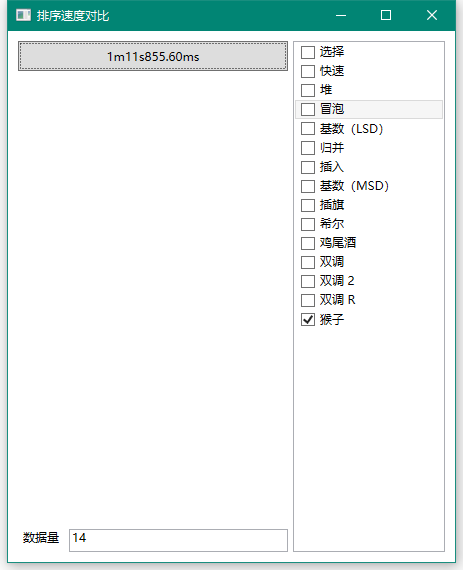
估计这辈子等不到了吧233……