无损文件压缩
无损压缩(下简称”压缩”)是计算机存储方面很重要的一种课题(至少在过去是),这是一种典型的时间换空间的方案。
过去由于存储介质普遍很贵,所以压缩方式存储文件可以更大化的利用存储介质的空间(就问你有没有见过只有40G的PC硬盘,想想都可怕)。
压缩,顾名思义就是把大文件的体积变小,让他在存储的时候能够少用一点存储空间,而且压缩后的文件能保证可以反向解算出来并且内容不会变化,但是压缩后的文件不能直接被文件系统识别和读取,需要先对文件进行解压之后才能读取其中内容,解压的时候会消耗一定时间,所以说是时间换空间。
压缩存储其实也就是对文件进行了特殊编码然后存储,今天主要介绍两种压缩编码:哈夫曼编码、LZ77编码。
哈夫曼编码
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种,是一种用于无损数据压缩的熵编码(权编码)算法。由美国计算机科学家大卫·霍夫曼(David Albert Huffman)在1952年发明。
这里我们先不管这个什么熵编码是啥意思,哈夫曼编码的核心是统计学原理。
简单举个例子,一篇英文文稿,也就是由a~z一共26种英文字母组成,而且有的字母出现频率很高,有些则很低。这时候我们就可以把频繁出现的部分替换为短一点的数据存储。比如如果字母e出现的频率很高,那么我们就用 bit: 0 表示字母e,这样所有有字母e的位置存储的大小都有 1 byte 变为了 1 bit,直接把字母e压缩了87.5%。其他的字母如果还有出现频次比较高的,也按照这个思路压缩,依次使用 bit: 1、bits: 00、bits: 01……这样向后不断填写替换原先的数据,这其实就是哈夫曼编码的核心思想。
所以说哈夫曼编码中我们需要预先知道所有要编码内容的出现频率,这里我们方便讨论,文件中按照字节看,也就是0~255一共256种可能字节,我们就以这256种字节作为编码对象简述一下过程:
1、读取源文件,统计这256种字节每一种出现的频数。
2、把统计得到的结果按照频数排序。
3、自底向上按照频数建立一个哈夫曼树。
4、根据树节点输出哈夫曼表。
5、按照哈夫曼表中的对应关系对数据重新进行编码并存储。
6、存储哈夫曼树/表信息用于解码。
这之中的重点就是哈夫曼树/表,下面通过对以上过程的详解穿插介绍一下这个树/表的来历。
哈夫曼编码过程
如果我们现在要压缩的数据是:
ABBCDADDE
统计这份数据各个字节出现的频数:
A B C D E
2 2 1 3 1
把数据按照频数排序:
C E A B D
1 1 2 2 3
下面就是建立哈夫曼树了。
我们先选择出现频数最低的两个节点(C,E),然后把它们放在同一个父节点下,父节点记录这两个节点一共出现的频数: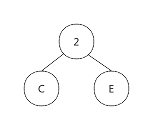
然后把他们的父节点与剩余的频数分布放到一起并排序(剔除C、E之后剩余的频数分布节点)
A B *(2) D
2 2 2 3
这里为什么把它放在A、B之后一会儿做说明。
然后又回到了排序好的状态,重复挑选最低频数过程,直到这个频数分布表只剩下一个节点。
*(9)
9
最终我们得到这样一个树: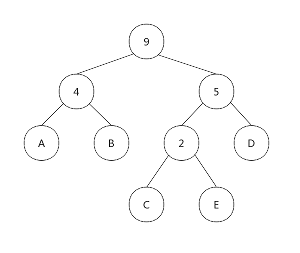
得到这棵树之后我们这样建立哈夫曼表:
先序遍历这棵树,然后记录路径,每向左一次记一个 0,向右一次记一个 1。
举个例子:
从根节点到E节点,我们的路径是“右左右”,所以E对应的编码是“101”
按照这种方法我们得到的哈夫曼表如下:
| Node | Code |
|---|---|
| A | 00 |
| B | 01 |
| C | 100 |
| D | 11 |
| E | 101 |
以上的1、0都是bit表示
所以这里你也可以思考一下,如果把新节点排序放在前面建立的树形态,这样你就理解为什么我们要把新节点放到后面了。
使用这些编码我们对原数据进行编码,对比原数据:
压缩后:
0001 0110 0110 0111 1101
=> 0x1667D
2.5 bytes
原数据:
ABBCDADDE
=> 0x414242434441444445
9 bytes
这样我们就把数据由原来的9字节压缩成了2.5字节。
把编码的数据重新存储,并且存储树信息,这样完整的哈夫曼编码过程就结束了。
哈夫曼解码过程
有编码肯定要有解码,解码失败那我们数据等于白存了。
哈夫曼的解码过程比较简单,还举刚刚的例子,假设我们已经拿到了编码和哈夫曼树。
由于编码是:
0x1667D => 0001 0110 0110 0111 1101
树参考刚刚的图,这里不再赘述。
我们按照编码时候的方式对数据进行展开,具体操作:
根据树信息和编码,从根结点开始,如果编码是0,去当前节点的的左子树,否则去右子树,如果新节点是一个叶子结点,那么就把数据输出然后退回根结点,重复这个过程直到数据结束。
比如我们按顺序读到了0,去往左子树,该点不是叶子,继续读又读到了0,继续前往左子树,这时候我们就到了节点A,输出A,然后退回根结点继续按照刚刚的方式读,一直到最后我们就得到了完整的原数据:ABBCDADDE。
哈夫曼编码的主要内容就是以上这些。
哈夫曼编码其他一些注意事项
树是不一定要存储的,哈夫曼本质是使用字典进行替换,如果你的字典预先写死在程序中,每一个程序压缩用的是同一个字典,这时候就不用单独存一份信息。
然而这么做的代价就是压缩的效果会由于文件的不同而不同,好的好,差的差。但是这种方法并不是不可取,有些主流的压缩算法中,有使用实数e和Π作为字典的。
那么我们讨论一下需要存储的情况。
树的存储有两种方式:重复节点存储和不重复节点存储。
我们建立哈夫曼树的时候,如果你亲自实现以下,你会发现最容易实现的算法就是重复节点存储方式,存储的形式就跟刚刚的例子一样,我们会把树的节点存成下面这样:
| Data | L-son | R-son |
|---|---|---|
| C | - | - |
| E | - | - |
| - | 0 | 1 |
| A | - | - |
| B | - | - |
| - | 3 | 4 |
| - | 0 | 1 |
| D | - | - |
| - | 6 | 7 |
| - | 3 | 4 |
| - | 6 | 7 |
| - | 9 | 10 |
- 代表无数据
最后一个节点是根
数据索引从上到下,从0开始
这样建树,第一是很快,第二是不需要复杂的树存储逻辑,存储新数据时不会影响以往的数据,但是代价也显而易见,这里面有很多冗余数据,必定造成空间浪费。
如果你直接保存这个树,无疑是很不理智的,如果要做到极致,树在保存的过程中应该把这些冗余的数据删除再保存。
关于压缩后的编码,还有一点理应存储一个文件解压后的长度,因为在当下的所有操作系统中,存储块默认最小是1字节,就刚刚的例子,我们是不可能保存2.5个字节到文件的,只能保存3个字节,如果保存了三个字节,必定造成后方存在 4 bit 的冗余数据,如果填成 0000 并且没有记录文件长,这四个 0 会被解释成AA,这显然是不对的,所以文件原长度是一定要保存的。
LZ77编码
LZ77是Abraham Lempel在1977年发表的论文中的无损数据压缩算法。与最小冗余编码器或者行程长度编码器不同,它是一种基于字典的、“滑动窗”的无损压缩算法,广泛应用于通信、计算机文件存档等方面,这个算法后来被证明等同于LZ78中首次出现的显式字典编码技术。
与哈夫曼不同,LZ77是一种动态的压缩算法,算法核心是通过前向缓冲区压缩后面的即将出现的数据,也是一种熵编码算法。他与哈夫曼最大的区别在于,LZ77不需要预先对文件进行全读处理,而是读取一段处理一段。
LZ77算法中,数据是一字节一字节读取的,然后根据前向缓冲区数据对后方数据进行压缩,算法流程:
1、读取文件流中的下一字节。
2、在前向缓冲区寻找与该数据相匹配的位置。
3、如果找到对应匹配,记录该位置并向后比较,直到数据出现不一致或者缓冲区耗尽,然后编码这一段数据写入结果;如果没有找到直接把该字符写入结果。
4、把刚刚读到的字符写入缓冲区。
5、如果文件流有剩余回到最初继续,否则编码结束。
LZ77的编码方式为:
| StartPos | Length | EndChar |
|---|---|---|
| 前向位置 | 长度 | 结束字符 |
只是这么讲的话,肯定你对LZ77的轮廓都无法想象出来,所以我们还是从例子出发详细描绘一下LZ77的一个大致轮廓。
编码
假设我们现在要压缩数据:
ABCDEABCDD
Hex:
0x41424344 45414243 4444
我们的缓冲区长度为8。
开始时:
| A | B | C | D | E | A | B | C | D | D | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ↑ |
前面缓冲区数据为空,所以直接把A写入结果,并且把A写入缓冲区。
| B | C | D | E | A | B | C | D | D | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | ↑ |
B在缓冲区中也没有匹配,继续按照刚刚的方式处理:输出文件,写入缓冲区。
这个过程一直持续到这个时候:
| * | A | B | C | D | D | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | ↑ |
这时候我们匹配到了A向后开始匹配数据。
| * | * | * | * | A | B | C | D | D | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | ↑ |
一共匹配到了4个字节,开始位置为3,长度为4,匹配结束末尾是D,所以我们编码数据输出(3,4,D)。
整个过程我们向结果中输出的数据为:ABCDE(3,4,D)
那怎么存这个数据呢?
其实LZ77算法在编码数据的时候一般需要一个标志位提示下面是编码的字段,比如取一个无意义字符0xFF,但是这这样的话在压缩非文本文件的时候0xFF还是会出现在有意义的字节中。这里我们可以根据C语言的格式化字符串处理这种情况。
回想一下C语言的格式化字符串,假设我们要输出一个“%”,那么我们需要在字符串中输入的是“%%”,这是一种处理数据的技巧,模仿一下,如果我们要存储一个有意义的0xFF而不希望解码的时候将它识别为标志,我们这里可以存储两个0xFF来表示这是一个有效的0xFF。
所以刚刚的例子中,我们最终存储的数据是(Hex):
0x41424344 45FF0304 44
比起原数据长度缩短了一个字节。
解码
LZ77的解码也比较简单,用我们刚刚编码的数据简单描述一下解码的流程:
ABCDE#34D
HEX:
0x41424344 45FF0304 44
我们依旧将缓冲区长度设为8(标志使用#表示):
| A | B | C | D | E | # | 3 | 4 | D | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ↑ |
读到A,非编码flag,直接输出结果,然后把A放入缓冲区。
| B | C | D | E | # | 3 | 4 | D | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | ↑ |
与刚刚一样,该过程一直持续到如下情况:
| # | 3 | 4 | D | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | ↑ |
读到flag,查看下一位不是flag,说明是起始字符,开始解码。
后续读入3,4,D,了解编码的数据是缓冲区索引3开始长度4的数据,并且末尾补充上D,所以我们输出数据为:ABCDD。
这样我们在整个流程中输出了:ABCDEABCDD。与原数据一致。
LZ77要注意的地方
第一个要注意的地方是,缓冲区在前向匹配的过程中应当闭锁,不再存入数据,直到本次匹配完成,否则超出当前缓冲区的部分,解码时其实是无法感知的,这个道理简单不再赘述。
第二个是,前向匹配中,不能只匹配数据第一次出现的位置,而是要匹配最佳的位置。举个例子:
| * | * | A | B | C | D | D | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | A | B | C | D | E | ↑ |
这时候两个A都匹配到了后面的数据,但是如果拿第一个A进行编码我们只能匹配到一位,后面的A却可以匹配到4位,所以这里更好的处理是使用第二个A作为匹配位置。
最后一点是,当你前向匹配到数据时,不一定要进行编码,简单来说,编码长度是固定的,因为它格式单一,而且肯定比一字节大,这时候如果你只匹配到一字节或者少于编码长度的字节数量,这里没必要把数据编码输出,因为编码后的数据比编码前还要大,得不偿失,还不如直接存储数据本身。
LZ77与哈夫曼这类熵编码总结
我们先直观感受一下这两个编码表现最好的时候能把数据压缩成什么样子吧:
哈夫曼的: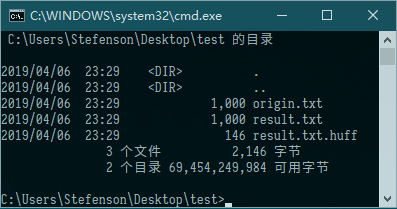
LZ77的: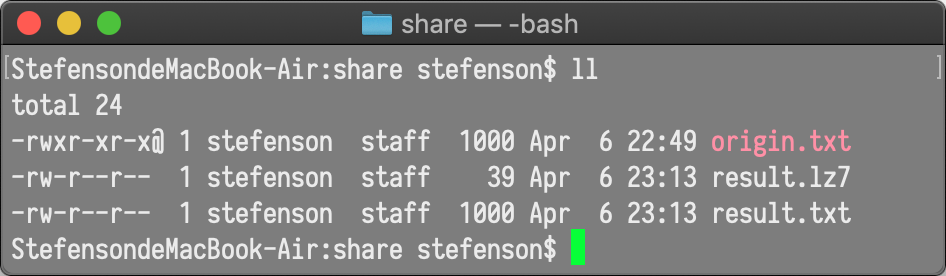
原谅我一个在Windows写的,一个在MacOS写的233。
写LZ77的时候手头刚好没有Windows环境,只能拿自己的Mac开撸C了。
这里你可能会说,哦呀压缩不错啊。
其实这个文件的内容很简单: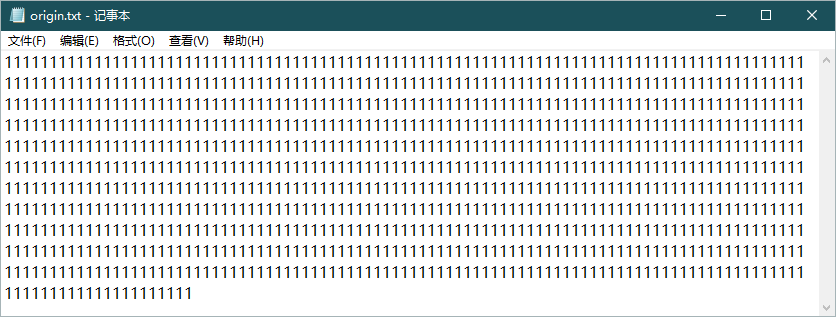
如果全世界的文件都长这样就好了(死)
好了好了不逗了,那对于一般情况的文件他们表现又如何呢?
我们先看PNG图片: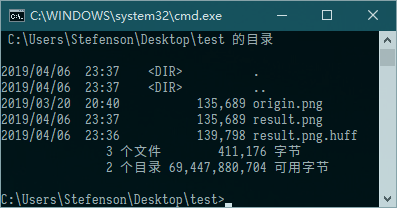
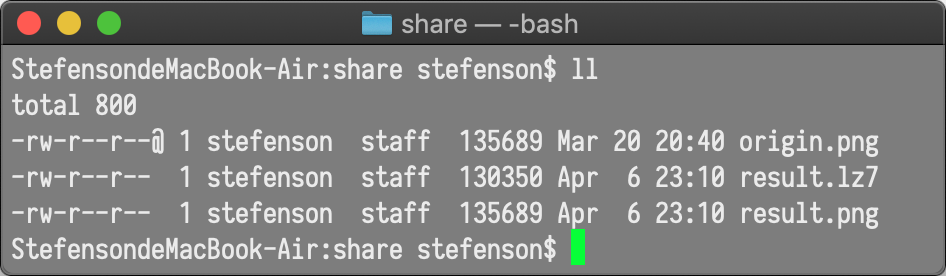
emmmmm,我有个问题想咨询一下哈夫曼同学,您对压缩的定义是不是有点偏差?
我们再来看看已经压缩的ZIP文档: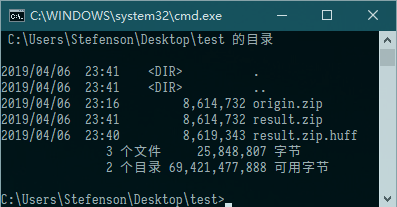
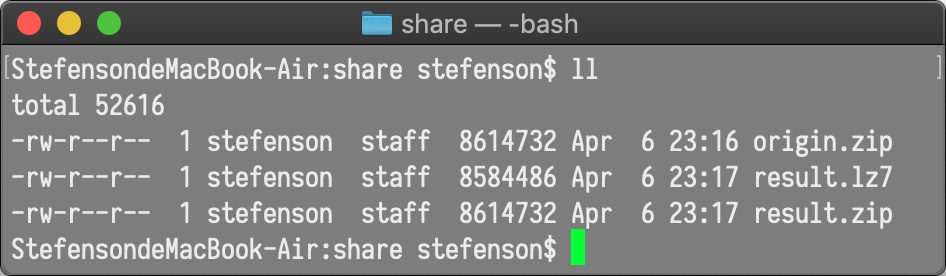
很不幸,哈夫曼同学依旧在进行反向压缩。
后面我多次尝试了一下,哈夫曼编码在压缩数据种类少,且数据频率差异明显的时候有很高的压缩率,在数据种类多,并且频率分布均匀的时候反而没有太大压缩效果。
LZ77则不同,LZ77无论什么文件几乎都能压缩那么一丢,因为它动态字典的特性,LZ77往往能比哈夫曼有更好的字典替换方案,并且LZ77不需要存储整棵树用于解码,如果编解码长度恒定甚至不需要存储缓冲区窗口长度。
所以在效果上来看,LZ77算法是优于哈夫曼的。
但是效果好也有很头疼的地方,LZ77最大的缺点是速度,非常慢,因为窗口的动态调整,他对数据的处理速度跟哈夫曼相比慢了不止一个数量级。
怎么优化他们呢?
这里我简单提供一个思路,留给读者们开发:
- 哈夫曼算法瓶颈其实是哈夫曼树的存储所占用的空间过多,还有就是选取字典的时候,如果你能匹配尽可能长的字节作为字典基,那么哈夫曼的效果其实是更好的,关键词:字典设置,树存储优化。
- LZ77算法的速度其实是可以实现并行计算的,在编码当前数据段的时候,如果已经确定结果,可以立即写好缓冲区进行下一次编码,不用非得等待本次编码完全结束再开始下一次编码。关键词:多线程。
- LZ77算法的压缩率,理论上与窗口长度正相关,因为当你窗口足够长的时候,你潜在可匹配的字符会更多,越有可能对后续数据进行编码存储,但是这里就有一个问题,那就是存储编码的时候需要使用大于一字节的数据存储数据开始位置和长度,这会造成文件中数据解释不统一,其实这个很好解决,不过后面我懒得写了233。关键词:增加窗口长。
后记
无损压缩算法的核心思想其实就是通过短字典替换长数据,最终使要存储的东西体积变得比原先小很多。
无损压缩算法其实还有很多变种,这里不再对他们进行一一介绍了,有兴趣的话读者们可以自行搜索一下资料,例如LZ78(这个其实挺有意思的,跟LZ77刚好相反的一种编码方式),LZW等等。
那么我们学了这些压缩算法能自己写一套压缩软件吗?当然可以,但是不建议你这么做,因为当下流行的几款主流压缩中,都是多年经验总结下来的结果,例如RAR,这个的压缩器是有专利的(但是解压器是开源的),RAR的效果大家是有目共睹的,但是它还是跑不出这些无损压缩算法的核心,只是通过很巧妙的方式把他们进行了优化和整合。
如果你真的想要尝试生产一个可用的压缩程序,我建议你去研究一下7z,这个开源的项目可以作为你快速了解一个无损压缩软件的入门项目,里面凝聚了很多大佬们的智慧。
另外,压缩是存在极限的,如果你想对这部分进行了解,我推荐你去看一看香农大佬的信息论,很棒的一本信息学著作(因为他是信息学创始人啊喂)。
结语
emmmmmmmmm……
突然发现半年前挖的坑……
>write date: 2019-4-5
终于把6个月之前的坑填进去了……